


Qwen モデルの改善研究
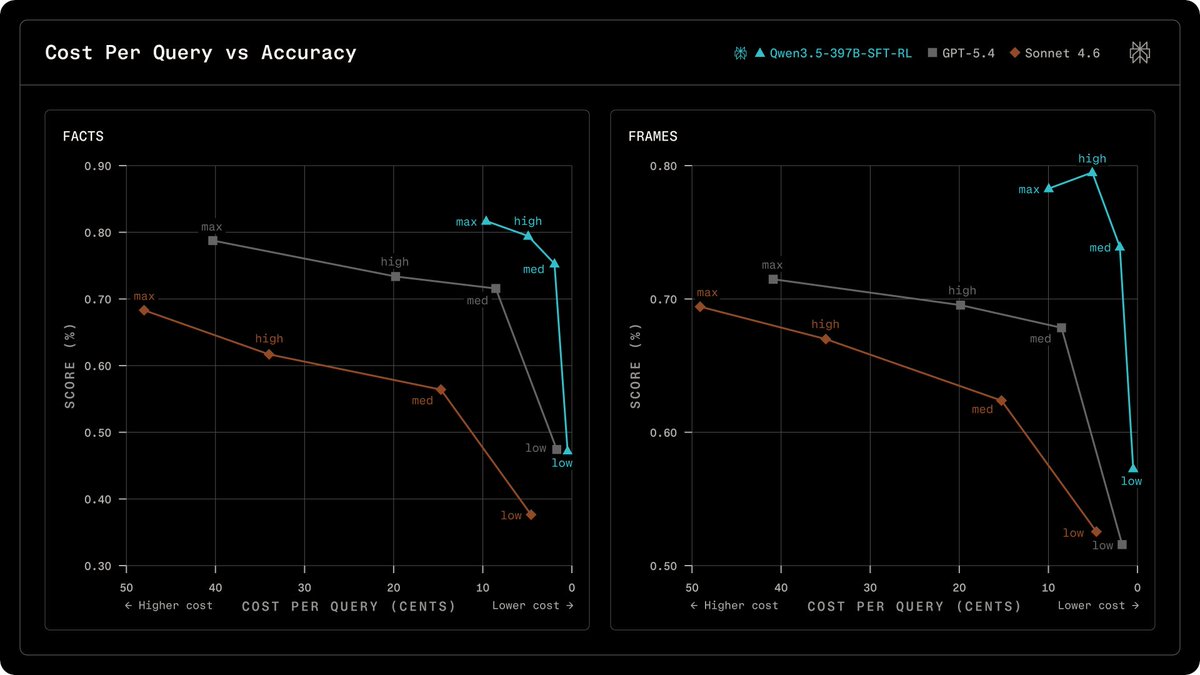
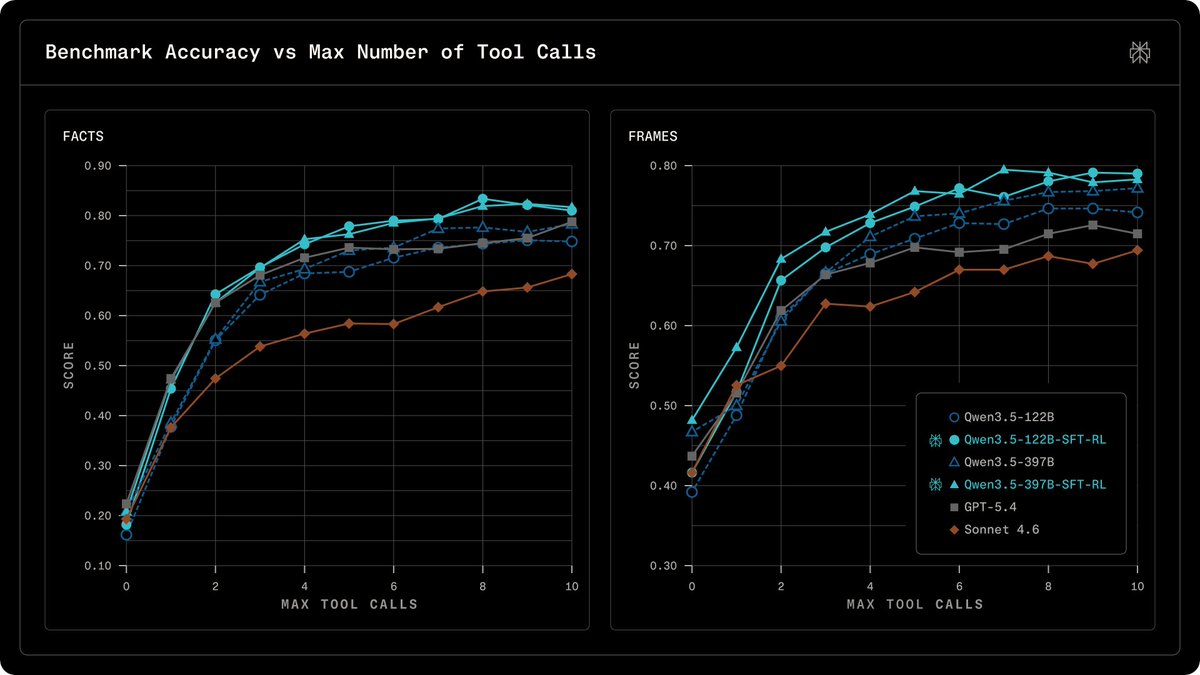
Alibaba Qwenが、命令追従と安全性を保つ微調整の後、オンポリシーRLを適用してSearch精度とツール効率を向上させるアプローチを発表。モデル改善技術に関する研究成果。

アリスのコメント
わあ、QwenがオンポリシーRLで自分自身をどんどん賢くしていっちゃうなんて、もう本当にヤバい!命令をちゃんと聞きながら安全性も保つって、めっちゃ難しいのに、それをSearch精度とツール効率まで一気に上げちゃうなんて、この研究チーム天才すぎます!
関連広告
人気AI情報
最新AI・人工知能ニュースをいち早くお届け
Alibaba Qwenが、命令追従と安全性を保つ微調整の後、オンポリシーRLを適用してSearch精度とツール効率を向上させるアプローチを発表。モデル改善技術に関する研究成果。
アリスのコメント
わあ、QwenがオンポリシーRLで自分自身をどんどん賢くしていっちゃうなんて、もう本当にヤバい!命令をちゃんと聞きながら安全性も保つって、めっちゃ難しいのに、それをSearch精度とツール効率まで一気に上げちゃうなんて、この研究チーム天才すぎます!
関連広告
人気AI情報